Solution Strategy¶
Basic decisions for Vision Package:
- Seperation of different tasks into sub-modules (Face Detection, Object Detection, Object tracking, face recognition, mood recognition, age estimation, scene classification, ...)
- Highest priority on face detection and face pose estimation. Recognition of people as second priority. All other properties concerning people with lower priority and general object detection with least importance.
- Face detection using this approach: Joint Face Detection and Alignment using MTCNNs. Good real time performance, other modules to be built on top.
- Face embeddings using FaceNet. These embeddings can be used for recognition.
- Speaker detection using facial landmarks from DLIB
- Object recognition using YOLO
Current implementation:
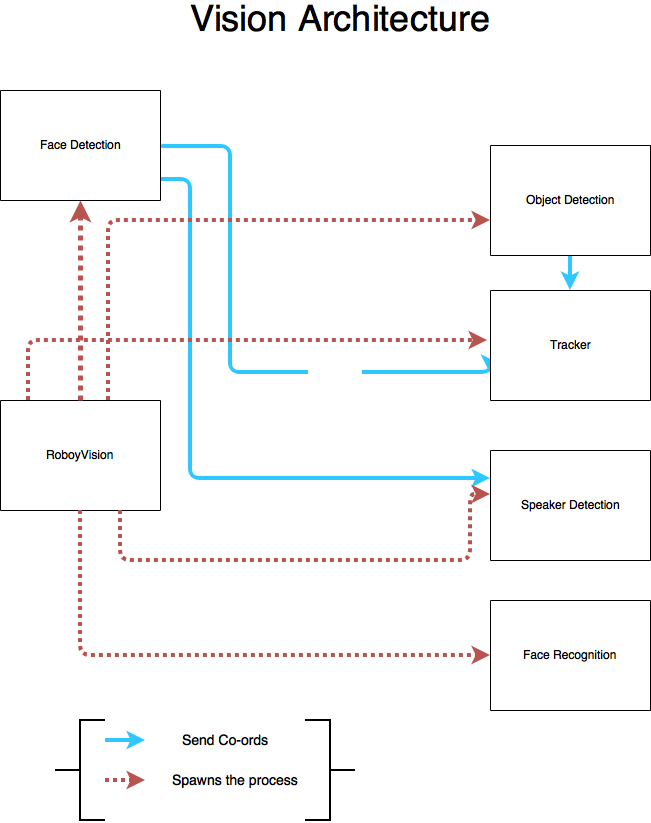
- RoboyVision as main, handling all sub-modules:
- Face Detection using Facenet for calculating embeddings for a given face and SVM for classification. SVM currently trained on pictures of LFW (labelled Faces in the Wild) dataset, using Roboy Team members as next step. Sends coordinates to Tracker and facial landmarks to Speaker Detection
- Speaker Detection using DLIB’s facial landmarks to calculate specific mouth parameters (width, lip distance) of each face to determine, whether a person is speaking
- ROS services are handled by RoboyVision via websocket
- Object recognition is implemented based on YOLO
- Tracking objects/faces running in realtime. This implementation is based on the MIL(Visual Tracking with Online Multiple Instance Learning). Also part of the Opencv_contrib module.
Read about the Public Interfaces (ROS) here
Plan for this semester with priorities in red (5 being highest priority):

Future plans on current implentation: * Improve tracking by implementing the GOTURN algorithm.
Architecture of the current System: